Rayen Feng

Hi, I'm Rayen I’m an aspiring data scientist. I've worked on a couple of person projects and this is my porfolio. You’re welcome to look around.
Check out my Blog!
Bella Beat Case Study
Analysis performed by: Rayen Feng
Date: June 27, 2022
As part of Google Data Analytics Certificate
Table of Contents
- Introduction
- Data preparation and processing
- Analysis of specific questions
- Sleep vs activity tracking usage
- Watch wear time relationships
- Conclusion and Recomendations
Introduction
Bellabeat is a high-tech manufacturer of heath products for women. By analyzing their smart products and using data-driven decision making can help discover and drive new opportunities for the company.
In this analysis, one of Bellabeat’s products will be chosen to undergo analysis using their smart device data to gain insight on how consumers are using smart devices. These insights will help guilde the marketing strategy for the company. High level reccomendations will be made to infrom Bellabeat’s marketing stategy. For this, exisiting trends in user activity using Fitbit data will be used.
The analysis hopes to seek to answer the following questions.
- What are some trends in smart device usage?
- How could these trends apply to Bellabeat customers?
-
How could these trends help influence Bellabeat marketing strategy?
- A clear summary of the business task
- A description of all data sources used
- Documentation of any cleaning or manipulation of data
- A summary of your analysis
- Supporting visualizations and key findings
- Your top high-level content recommendations based on your analysis
Data Preperation and processing
As mentioned in the introduction, the following analysis will use the Kaggle dataset which contains personal fitness tracker from thirty fitbit users. Thirty eligible Fitbit users consented to the submission of personal tracker data, including minute-level output for physical activity, heart rate, and sleep monitoring. It includes information about daily activity, steps, and heart rate that can be used to explore users’ habits. For this analysis, python and the pandas dataframe package will be used for data cleaning, manipulation and analysis. Additionally, packages such as matplotlib and seaborn will be used to visualize and present the data.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import datetime
pd.options.mode.chained_assignment = None # default='warn'
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/minuteCaloriesNarrow_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/weightLogInfo_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/sleepDay_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/dailyIntensities_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/minuteIntensitiesWide_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/minuteMETsNarrow_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/dailyCalories_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/hourlyCalories_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/heartrate_seconds_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/minuteSleep_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/hourlyIntensities_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/hourlySteps_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/minuteStepsNarrow_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/dailySteps_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/minuteStepsWide_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/minuteIntensitiesNarrow_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/minuteCaloriesWide_merged.csv
/kaggle/input/fitbit/Fitabase Data 4.12.16-5.12.16/dailyActivity_merged.csv
Importing data
After previewing the data, a few datasets were selected and imported to investigate further.
activity_daily = pd.read_csv ('../input/fitbit/Fitabase Data 4.12.16-5.12.16/dailyActivity_merged.csv')
heart_rate = pd.read_csv ('../input/fitbit/Fitabase Data 4.12.16-5.12.16/heartrate_seconds_merged.csv')
sleepDay_merged = pd.read_csv ('../input/fitbit/Fitabase Data 4.12.16-5.12.16/sleepDay_merged.csv')
minuteSleep_merged = pd.read_csv ('../input/fitbit/Fitabase Data 4.12.16-5.12.16/minuteSleep_merged.csv')
minuteMETsNarrow_merged = pd.read_csv ('../input/fitbit/Fitabase Data 4.12.16-5.12.16/minuteMETsNarrow_merged.csv')
Previewing core data trends
The first step will be to preview the main dataset, which is the daily_activity_merged dataset. This dataset contains the activity data of all 33 participlants and the breakdown for their activity for 30 days from April 12, 2016 to May 12, 2016. Looking at the rows shown below, the dataset contains the breakdown of the type of activity intensity, the logged distances and durations of summarized daily.
display(activity_daily)
| Id | ActivityDate | TotalSteps | TotalDistance | TrackerDistance | LoggedActivitiesDistance | VeryActiveDistance | ModeratelyActiveDistance | LightActiveDistance | SedentaryActiveDistance | VeryActiveMinutes | FairlyActiveMinutes | LightlyActiveMinutes | SedentaryMinutes | Calories | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1503960366 | 4/12/2016 | 13162 | 8.500000 | 8.500000 | 0.0 | 1.88 | 0.55 | 6.06 | 0.00 | 25 | 13 | 328 | 728 | 1985 |
| 1 | 1503960366 | 4/13/2016 | 10735 | 6.970000 | 6.970000 | 0.0 | 1.57 | 0.69 | 4.71 | 0.00 | 21 | 19 | 217 | 776 | 1797 |
| 2 | 1503960366 | 4/14/2016 | 10460 | 6.740000 | 6.740000 | 0.0 | 2.44 | 0.40 | 3.91 | 0.00 | 30 | 11 | 181 | 1218 | 1776 |
| 3 | 1503960366 | 4/15/2016 | 9762 | 6.280000 | 6.280000 | 0.0 | 2.14 | 1.26 | 2.83 | 0.00 | 29 | 34 | 209 | 726 | 1745 |
| 4 | 1503960366 | 4/16/2016 | 12669 | 8.160000 | 8.160000 | 0.0 | 2.71 | 0.41 | 5.04 | 0.00 | 36 | 10 | 221 | 773 | 1863 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 935 | 8877689391 | 5/8/2016 | 10686 | 8.110000 | 8.110000 | 0.0 | 1.08 | 0.20 | 6.80 | 0.00 | 17 | 4 | 245 | 1174 | 2847 |
| 936 | 8877689391 | 5/9/2016 | 20226 | 18.250000 | 18.250000 | 0.0 | 11.10 | 0.80 | 6.24 | 0.05 | 73 | 19 | 217 | 1131 | 3710 |
| 937 | 8877689391 | 5/10/2016 | 10733 | 8.150000 | 8.150000 | 0.0 | 1.35 | 0.46 | 6.28 | 0.00 | 18 | 11 | 224 | 1187 | 2832 |
| 938 | 8877689391 | 5/11/2016 | 21420 | 19.559999 | 19.559999 | 0.0 | 13.22 | 0.41 | 5.89 | 0.00 | 88 | 12 | 213 | 1127 | 3832 |
| 939 | 8877689391 | 5/12/2016 | 8064 | 6.120000 | 6.120000 | 0.0 | 1.82 | 0.04 | 4.25 | 0.00 | 23 | 1 | 137 | 770 | 1849 |
940 rows × 15 columns
display(activity_daily.max())
activity_daily.min()
Id 8877689391
ActivityDate 5/9/2016
TotalSteps 36019
TotalDistance 28.030001
TrackerDistance 28.030001
LoggedActivitiesDistance 4.942142
VeryActiveDistance 21.92
ModeratelyActiveDistance 6.48
LightActiveDistance 10.71
SedentaryActiveDistance 0.11
VeryActiveMinutes 210
FairlyActiveMinutes 143
LightlyActiveMinutes 518
SedentaryMinutes 1440
Calories 4900
dtype: object
Id 1503960366
ActivityDate 4/12/2016
TotalSteps 0
TotalDistance 0.0
TrackerDistance 0.0
LoggedActivitiesDistance 0.0
VeryActiveDistance 0.0
ModeratelyActiveDistance 0.0
LightActiveDistance 0.0
SedentaryActiveDistance 0.0
VeryActiveMinutes 0
FairlyActiveMinutes 0
LightlyActiveMinutes 0
SedentaryMinutes 0
Calories 0
dtype: object
A quick conversion of the activity date to datetime format can be done to clean the dataset.
activity_daily['ActivityDate'] = pd.to_datetime(activity_daily['ActivityDate'])
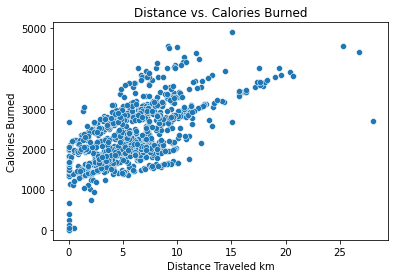
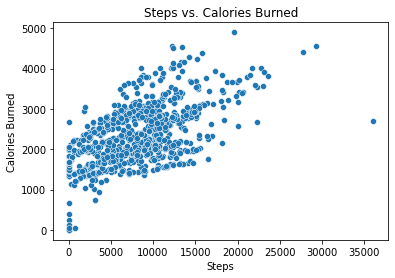
To check the general validity and accuracy of this data, a quick check can be performed by plotting the relationship of two variables. It’s known that generally, the more distance traveled or the more steps walked, the more calories are burned. By plotting these two variables in a scatterplot, a general upward trend of these two varibles is observed, which proves the validity of this data.
sns.scatterplot(
x='TotalDistance',
y='Calories',
data = activity_daily,
)
plt.title("Distance vs. Calories Burned")
plt.xlabel("Distance Traveled km")
plt.ylabel("Calories Burned")
plt.show()
sns.scatterplot(
x='TotalSteps',
y='Calories',
data = activity_daily,
)
plt.title("Steps vs. Calories Burned")
plt.xlabel("Steps")
plt.ylabel("Calories Burned")
plt.show()
Preparing User data
The activity data can be grouped and then grouped by their user ID to find general average information of each user. Additionally, a quick check can be made to check that the total users in this dataset is 33.
activity_daily_indv = activity_daily.groupby(['Id']).mean()
display(activity_daily_indv.sort_values(by = ["Calories"], ascending = False).head(n=5))
print(len(activity_daily_indv))
| TotalSteps | TotalDistance | TrackerDistance | LoggedActivitiesDistance | VeryActiveDistance | ModeratelyActiveDistance | LightActiveDistance | SedentaryActiveDistance | VeryActiveMinutes | FairlyActiveMinutes | LightlyActiveMinutes | SedentaryMinutes | Calories | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Id | |||||||||||||
| 8378563200 | 8717.709677 | 6.913548 | 6.913548 | 1.116158 | 2.503548 | 0.519032 | 3.889355 | 0.000000 | 58.677419 | 10.258065 | 156.096774 | 716.129032 | 3436.580645 |
| 8877689391 | 16040.032258 | 13.212903 | 13.212903 | 0.000000 | 6.637419 | 0.337742 | 6.188710 | 0.005161 | 66.064516 | 9.935484 | 234.709677 | 1112.870968 | 3420.258065 |
| 5577150313 | 8304.433333 | 6.213333 | 6.213333 | 0.000000 | 3.113667 | 0.658000 | 2.428000 | 0.000000 | 87.333333 | 29.833333 | 147.933333 | 754.433333 | 3359.633333 |
| 4388161847 | 10813.935484 | 8.393226 | 8.393226 | 0.000000 | 1.719355 | 0.901935 | 5.396129 | 0.000000 | 23.161290 | 20.354839 | 229.354839 | 836.677419 | 3093.870968 |
| 4702921684 | 8572.064516 | 6.955161 | 6.955161 | 0.000000 | 0.417419 | 1.304839 | 5.225484 | 0.000000 | 5.129032 | 26.032258 | 237.483871 | 766.419355 | 2965.548387 |
33
One last consideration to prepare this data is the participation rate of the users. Users who didn’t wear the watch as much might have a negative impact on the data, especially when considering what the participants use the watch for. To account for this, the users that participated less will have to be filtered out. This threshold will be set at a 80% participation rate.
By splitting these users into two groups, there is flexibility to see trends between the groups as well.
# create a function that shows the activity data for one user for a specific dataframe
def show_user_data(df,user_id):
t = df[df.Id == user_id]
return(t)
# Finding participants who took than 50 total steps per day
unique_ids = activity_daily['Id'].unique()
days_skip_arr = []
for i in unique_ids:
person_data = show_user_data(activity_daily,i)
day_skipped = person_data[person_data.TotalSteps <= 50]
days_skipped = len(day_skipped)
days_skip_arr.append(days_skipped)
day_skip_by_id = {'Id': unique_ids, 'days_skipped':days_skip_arr }
day_skip_by_ids= pd.DataFrame(data=day_skip_by_id)
# seperating the participants ids to 80% active and inactive
day_skip_by_ids_sorted = day_skip_by_ids.sort_values(by = ['days_skipped'], ascending = False).reset_index(drop = True)
ids_80_percent_inactive = day_skip_by_ids_sorted.iloc[:5]
ids_80_percent_active = day_skip_by_ids_sorted.iloc[5:]
# splitting the activity_data between active and inactive users
active_users = activity_daily[activity_daily.Id.isin(ids_80_percent_active.Id)]
inactive_users = activity_daily[activity_daily.Id.isin(ids_80_percent_inactive.Id)]
display(active_users)
display(inactive_users)
| Id | ActivityDate | TotalSteps | TotalDistance | TrackerDistance | LoggedActivitiesDistance | VeryActiveDistance | ModeratelyActiveDistance | LightActiveDistance | SedentaryActiveDistance | VeryActiveMinutes | FairlyActiveMinutes | LightlyActiveMinutes | SedentaryMinutes | Calories | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1503960366 | 2016-04-12 | 13162 | 8.500000 | 8.500000 | 0.0 | 1.88 | 0.55 | 6.06 | 0.00 | 25 | 13 | 328 | 728 | 1985 |
| 1 | 1503960366 | 2016-04-13 | 10735 | 6.970000 | 6.970000 | 0.0 | 1.57 | 0.69 | 4.71 | 0.00 | 21 | 19 | 217 | 776 | 1797 |
| 2 | 1503960366 | 2016-04-14 | 10460 | 6.740000 | 6.740000 | 0.0 | 2.44 | 0.40 | 3.91 | 0.00 | 30 | 11 | 181 | 1218 | 1776 |
| 3 | 1503960366 | 2016-04-15 | 9762 | 6.280000 | 6.280000 | 0.0 | 2.14 | 1.26 | 2.83 | 0.00 | 29 | 34 | 209 | 726 | 1745 |
| 4 | 1503960366 | 2016-04-16 | 12669 | 8.160000 | 8.160000 | 0.0 | 2.71 | 0.41 | 5.04 | 0.00 | 36 | 10 | 221 | 773 | 1863 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 935 | 8877689391 | 2016-05-08 | 10686 | 8.110000 | 8.110000 | 0.0 | 1.08 | 0.20 | 6.80 | 0.00 | 17 | 4 | 245 | 1174 | 2847 |
| 936 | 8877689391 | 2016-05-09 | 20226 | 18.250000 | 18.250000 | 0.0 | 11.10 | 0.80 | 6.24 | 0.05 | 73 | 19 | 217 | 1131 | 3710 |
| 937 | 8877689391 | 2016-05-10 | 10733 | 8.150000 | 8.150000 | 0.0 | 1.35 | 0.46 | 6.28 | 0.00 | 18 | 11 | 224 | 1187 | 2832 |
| 938 | 8877689391 | 2016-05-11 | 21420 | 19.559999 | 19.559999 | 0.0 | 13.22 | 0.41 | 5.89 | 0.00 | 88 | 12 | 213 | 1127 | 3832 |
| 939 | 8877689391 | 2016-05-12 | 8064 | 6.120000 | 6.120000 | 0.0 | 1.82 | 0.04 | 4.25 | 0.00 | 23 | 1 | 137 | 770 | 1849 |
792 rows × 15 columns
| Id | ActivityDate | TotalSteps | TotalDistance | TrackerDistance | LoggedActivitiesDistance | VeryActiveDistance | ModeratelyActiveDistance | LightActiveDistance | SedentaryActiveDistance | VeryActiveMinutes | FairlyActiveMinutes | LightlyActiveMinutes | SedentaryMinutes | Calories | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 92 | 1844505072 | 2016-04-12 | 6697 | 4.43 | 4.43 | 0.0 | 0.0 | 0.0 | 4.43 | 0.0 | 0 | 0 | 339 | 1101 | 2030 |
| 93 | 1844505072 | 2016-04-13 | 4929 | 3.26 | 3.26 | 0.0 | 0.0 | 0.0 | 3.26 | 0.0 | 0 | 0 | 248 | 1192 | 1860 |
| 94 | 1844505072 | 2016-04-14 | 7937 | 5.25 | 5.25 | 0.0 | 0.0 | 0.0 | 5.23 | 0.0 | 0 | 0 | 373 | 843 | 2130 |
| 95 | 1844505072 | 2016-04-15 | 3844 | 2.54 | 2.54 | 0.0 | 0.0 | 0.0 | 2.54 | 0.0 | 0 | 0 | 176 | 527 | 1725 |
| 96 | 1844505072 | 2016-04-16 | 3414 | 2.26 | 2.26 | 0.0 | 0.0 | 0.0 | 2.26 | 0.0 | 0 | 0 | 147 | 1293 | 1657 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 904 | 8792009665 | 2016-05-06 | 0 | 0.00 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0 | 0 | 0 | 1440 | 1688 |
| 905 | 8792009665 | 2016-05-07 | 0 | 0.00 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0 | 0 | 0 | 1440 | 1688 |
| 906 | 8792009665 | 2016-05-08 | 0 | 0.00 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0 | 0 | 0 | 1440 | 1688 |
| 907 | 8792009665 | 2016-05-09 | 0 | 0.00 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0 | 0 | 0 | 1440 | 1688 |
| 908 | 8792009665 | 2016-05-10 | 0 | 0.00 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0 | 0 | 0 | 48 | 57 |
148 rows × 15 columns
Analysis of specific questions
To answer the question about how participants use smartwatches, a few trends need to be analyzed further.
- Do people have a preference towards using the watch as a sleep tracker or as an activity tracker?
- What kinds of activities does a user do while using the watch?
- How long do they have their watch on for the day?
To calculate the type of activity that the user does most frequently while wearing the watch, the time from each activty can be summed.
sum_col_inact = inactive_users["VeryActiveMinutes"] + inactive_users["FairlyActiveMinutes"] + inactive_users["LightlyActiveMinutes"] + inactive_users["SedentaryMinutes"]
inactive_users["Total_Minutes"] = sum_col_inact
sum_col_act = active_users["VeryActiveMinutes"] + active_users["FairlyActiveMinutes"] + active_users["LightlyActiveMinutes"] + active_users["SedentaryMinutes"]
active_users["Total_Minutes"] = sum_col_act
inactive_users
| Id | ActivityDate | TotalSteps | TotalDistance | TrackerDistance | LoggedActivitiesDistance | VeryActiveDistance | ModeratelyActiveDistance | LightActiveDistance | SedentaryActiveDistance | VeryActiveMinutes | FairlyActiveMinutes | LightlyActiveMinutes | SedentaryMinutes | Calories | Total_Minutes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 92 | 1844505072 | 2016-04-12 | 6697 | 4.43 | 4.43 | 0.0 | 0.0 | 0.0 | 4.43 | 0.0 | 0 | 0 | 339 | 1101 | 2030 | 1440 |
| 93 | 1844505072 | 2016-04-13 | 4929 | 3.26 | 3.26 | 0.0 | 0.0 | 0.0 | 3.26 | 0.0 | 0 | 0 | 248 | 1192 | 1860 | 1440 |
| 94 | 1844505072 | 2016-04-14 | 7937 | 5.25 | 5.25 | 0.0 | 0.0 | 0.0 | 5.23 | 0.0 | 0 | 0 | 373 | 843 | 2130 | 1216 |
| 95 | 1844505072 | 2016-04-15 | 3844 | 2.54 | 2.54 | 0.0 | 0.0 | 0.0 | 2.54 | 0.0 | 0 | 0 | 176 | 527 | 1725 | 703 |
| 96 | 1844505072 | 2016-04-16 | 3414 | 2.26 | 2.26 | 0.0 | 0.0 | 0.0 | 2.26 | 0.0 | 0 | 0 | 147 | 1293 | 1657 | 1440 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 904 | 8792009665 | 2016-05-06 | 0 | 0.00 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0 | 0 | 0 | 1440 | 1688 | 1440 |
| 905 | 8792009665 | 2016-05-07 | 0 | 0.00 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0 | 0 | 0 | 1440 | 1688 | 1440 |
| 906 | 8792009665 | 2016-05-08 | 0 | 0.00 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0 | 0 | 0 | 1440 | 1688 | 1440 |
| 907 | 8792009665 | 2016-05-09 | 0 | 0.00 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0 | 0 | 0 | 1440 | 1688 | 1440 |
| 908 | 8792009665 | 2016-05-10 | 0 | 0.00 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0 | 0 | 0 | 48 | 57 | 48 |
148 rows × 16 columns
display(active_users)
total_VAM = sum(active_users["VeryActiveMinutes"])
total_FAM = sum(active_users["FairlyActiveMinutes"])
toatl_LAM = sum(active_users["LightlyActiveMinutes"])
total_SEM = sum(active_users["SedentaryMinutes"])
total_min = sum(sum_col_act)
y = np.array([total_VAM,total_FAM,toatl_LAM,total_SEM])
mylabels = ["VeryActiveMinutes", "FairlyActiveMinutes", "LightlyActiveMinutes", "SedentaryMinutes"]
colors = sns.color_palette('pastel')
plt.pie(y, labels = mylabels, colors = colors)
plt.title("Time spent on type of Activity")
plt.show()
| Id | ActivityDate | TotalSteps | TotalDistance | TrackerDistance | LoggedActivitiesDistance | VeryActiveDistance | ModeratelyActiveDistance | LightActiveDistance | SedentaryActiveDistance | VeryActiveMinutes | FairlyActiveMinutes | LightlyActiveMinutes | SedentaryMinutes | Calories | Total_Minutes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1503960366 | 2016-04-12 | 13162 | 8.500000 | 8.500000 | 0.0 | 1.88 | 0.55 | 6.06 | 0.00 | 25 | 13 | 328 | 728 | 1985 | 1094 |
| 1 | 1503960366 | 2016-04-13 | 10735 | 6.970000 | 6.970000 | 0.0 | 1.57 | 0.69 | 4.71 | 0.00 | 21 | 19 | 217 | 776 | 1797 | 1033 |
| 2 | 1503960366 | 2016-04-14 | 10460 | 6.740000 | 6.740000 | 0.0 | 2.44 | 0.40 | 3.91 | 0.00 | 30 | 11 | 181 | 1218 | 1776 | 1440 |
| 3 | 1503960366 | 2016-04-15 | 9762 | 6.280000 | 6.280000 | 0.0 | 2.14 | 1.26 | 2.83 | 0.00 | 29 | 34 | 209 | 726 | 1745 | 998 |
| 4 | 1503960366 | 2016-04-16 | 12669 | 8.160000 | 8.160000 | 0.0 | 2.71 | 0.41 | 5.04 | 0.00 | 36 | 10 | 221 | 773 | 1863 | 1040 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 935 | 8877689391 | 2016-05-08 | 10686 | 8.110000 | 8.110000 | 0.0 | 1.08 | 0.20 | 6.80 | 0.00 | 17 | 4 | 245 | 1174 | 2847 | 1440 |
| 936 | 8877689391 | 2016-05-09 | 20226 | 18.250000 | 18.250000 | 0.0 | 11.10 | 0.80 | 6.24 | 0.05 | 73 | 19 | 217 | 1131 | 3710 | 1440 |
| 937 | 8877689391 | 2016-05-10 | 10733 | 8.150000 | 8.150000 | 0.0 | 1.35 | 0.46 | 6.28 | 0.00 | 18 | 11 | 224 | 1187 | 2832 | 1440 |
| 938 | 8877689391 | 2016-05-11 | 21420 | 19.559999 | 19.559999 | 0.0 | 13.22 | 0.41 | 5.89 | 0.00 | 88 | 12 | 213 | 1127 | 3832 | 1440 |
| 939 | 8877689391 | 2016-05-12 | 8064 | 6.120000 | 6.120000 | 0.0 | 1.82 | 0.04 | 4.25 | 0.00 | 23 | 1 | 137 | 770 | 1849 | 931 |
792 rows × 16 columns
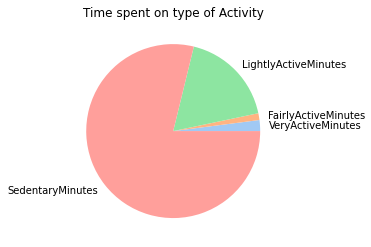
Key Findings of user activity
From this analysis, we can see the majority of users are engaged in sedentrary activity,followed by Light Activity. Only a small amount of time is spend performing moderate to intense activity
This data can show:
- It may be better to advertise smartwatch products to the general public as a tool that tracks general heath and fitness instead of a precise measurment tool for hardcore athelets.
- On the same note, this means that the advertisements should focus more on emphasizing the ease of usability and simplicity for tracking basic features such as heart rate and such, rather than marketing the wide use of advaced and complex features.
- Since most users spend times wearing the watch while inactive,and in a more causual setting, it might be good to focus efforts on emphasizing the asthetics of the watch.
Sleep vs. activity tracking usage
For this, a quick comparison between the number of users who logged into the sleep data vs the total number of users will be compared. To analyze this, the sleepDay_merged will be used to count the users who tracked their sleep.
display(sleepDay_merged)
| Id | SleepDay | TotalSleepRecords | TotalMinutesAsleep | TotalTimeInBed | |
|---|---|---|---|---|---|
| 0 | 1503960366 | 4/12/2016 12:00:00 AM | 1 | 327 | 346 |
| 1 | 1503960366 | 4/13/2016 12:00:00 AM | 2 | 384 | 407 |
| 2 | 1503960366 | 4/15/2016 12:00:00 AM | 1 | 412 | 442 |
| 3 | 1503960366 | 4/16/2016 12:00:00 AM | 2 | 340 | 367 |
| 4 | 1503960366 | 4/17/2016 12:00:00 AM | 1 | 700 | 712 |
| ... | ... | ... | ... | ... | ... |
| 408 | 8792009665 | 4/30/2016 12:00:00 AM | 1 | 343 | 360 |
| 409 | 8792009665 | 5/1/2016 12:00:00 AM | 1 | 503 | 527 |
| 410 | 8792009665 | 5/2/2016 12:00:00 AM | 1 | 415 | 423 |
| 411 | 8792009665 | 5/3/2016 12:00:00 AM | 1 | 516 | 545 |
| 412 | 8792009665 | 5/4/2016 12:00:00 AM | 1 | 439 | 463 |
413 rows × 5 columns
# getting the number of users using the sleep tracking device / 30 users
unique_ids_sleep = sleepDay_merged['Id'].unique()
len(unique_ids_sleep)
unique_ids_sleep_mins = minuteSleep_merged['Id'].unique()
print("number of users who wear a watch to sleep: " + str(len(unique_ids_sleep_mins)))
number of users who wear a watch to sleep: 24
Now, it’s known that the number of users who wear the watch is less than the total number participants. However, this is not yet conclusive to whether or not users prefer one feature or the other. In order to eliminate the possibility of users who prefer not to wear the watch regardless, a additional process must be taken to exclude those users from this case.
active_user_id = active_users['Id'].unique()
unique_ids_sleep_mins
count_of_users = set(active_user_id).intersection(unique_ids_sleep_mins)
print("active users: " + str(len(active_user_id)))
print("active users who wear the watch to sleep: " + str(len(count_of_users)))
active users: 28
active users who wear the watch to sleep: 19
this means that 19 out of the 28 active users actually track their sleep data. This might mean that they are uncomforatable wearing this to bed. It might be better for bellafit to focus on marketing targeting the activity. Or, this can be a good oprortunity to fill in the gap and advertise it as a comfortable watch that can also track the sleep data.
Watch wear time relationships
there are three methods to track the watch time
- Through the activity data and counting the total active minutes
- Through the heart monitor
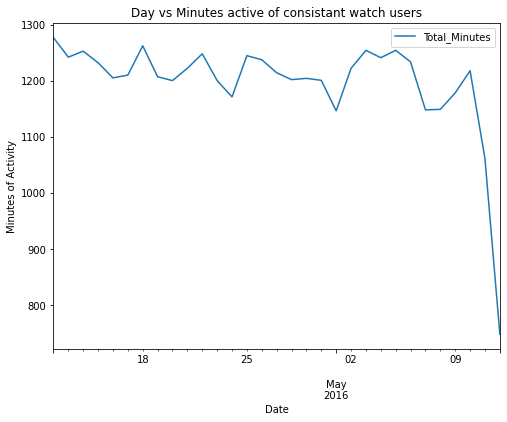
To begin with, a quick look at the watch useage over time can be analyzed to see if there is correlation between the time into the project and the watch wear time.
avg_active_mins_daily_active = active_users.groupby(['ActivityDate']).mean()
avg_active_mins_daily_inactive = inactive_users.groupby(['ActivityDate']).mean()
avg_active_mins_daily_active.plot(y = "Total_Minutes", figsize = (8,6))
plt.title("Day vs Minutes active of consistant watch users")
plt.xlabel("Date")
plt.ylabel("Minutes of Activity")
Text(0, 0.5, 'Minutes of Activity')
avg_active_mins_daily_inactive.plot(y = "Total_Minutes", figsize = (8,6))
plt.title("Day vs Minutes active of inconsistant watch users")
plt.xlabel("Date")
plt.ylabel("Minutes of Activity")
Text(0, 0.5, 'Minutes of Activity')
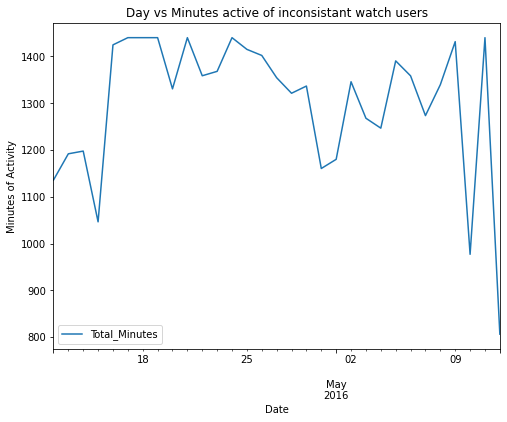
From this analysis, it can be noted that there is no direct correlation between the time and the duration of usage. However, it is noted that there might be a possibility that the participants had a lower average usage of the watch towards the end of the periods.
Finding average wear time
if the start day and wearing the watch is 7AM for example and the end time is 9:00PM assuming that when there’s no meter it means that the watch is off the person. By knowing what time they like to take it on and off shows if they like to track sleep or not.
display(heart_rate)
| Id | Time | Value | |
|---|---|---|---|
| 0 | 2022484408 | 4/12/2016 7:21:00 AM | 97 |
| 1 | 2022484408 | 4/12/2016 7:21:05 AM | 102 |
| 2 | 2022484408 | 4/12/2016 7:21:10 AM | 105 |
| 3 | 2022484408 | 4/12/2016 7:21:20 AM | 103 |
| 4 | 2022484408 | 4/12/2016 7:21:25 AM | 101 |
| ... | ... | ... | ... |
| 2483653 | 8877689391 | 5/12/2016 2:43:53 PM | 57 |
| 2483654 | 8877689391 | 5/12/2016 2:43:58 PM | 56 |
| 2483655 | 8877689391 | 5/12/2016 2:44:03 PM | 55 |
| 2483656 | 8877689391 | 5/12/2016 2:44:18 PM | 55 |
| 2483657 | 8877689391 | 5/12/2016 2:44:28 PM | 56 |
2483658 rows × 3 columns
# converting to datetime format
heart_rate['Time'] = pd.to_datetime(heart_rate['Time'], format= "%m/%d/%Y %I:%M:%S %p")
#creating new date and time columns
heart_rate['new_date'] = [d.date() for d in heart_rate['Time']]
heart_rate['new_time'] = [d.time() for d in heart_rate['Time']]
heart_rate
| Id | Time | Value | new_date | new_time | |
|---|---|---|---|---|---|
| 0 | 2022484408 | 2016-04-12 07:21:00 | 97 | 2016-04-12 | 07:21:00 |
| 1 | 2022484408 | 2016-04-12 07:21:05 | 102 | 2016-04-12 | 07:21:05 |
| 2 | 2022484408 | 2016-04-12 07:21:10 | 105 | 2016-04-12 | 07:21:10 |
| 3 | 2022484408 | 2016-04-12 07:21:20 | 103 | 2016-04-12 | 07:21:20 |
| 4 | 2022484408 | 2016-04-12 07:21:25 | 101 | 2016-04-12 | 07:21:25 |
| ... | ... | ... | ... | ... | ... |
| 2483653 | 8877689391 | 2016-05-12 14:43:53 | 57 | 2016-05-12 | 14:43:53 |
| 2483654 | 8877689391 | 2016-05-12 14:43:58 | 56 | 2016-05-12 | 14:43:58 |
| 2483655 | 8877689391 | 2016-05-12 14:44:03 | 55 | 2016-05-12 | 14:44:03 |
| 2483656 | 8877689391 | 2016-05-12 14:44:18 | 55 | 2016-05-12 | 14:44:18 |
| 2483657 | 8877689391 | 2016-05-12 14:44:28 | 56 | 2016-05-12 | 14:44:28 |
2483658 rows × 5 columns
unique_dates= heart_rate['new_date'].unique()
unique_ids_heart = heart_rate['Id'].unique()
count_of_users_heart = set(active_user_id).intersection(unique_ids_heart)
print(str(len(count_of_users_heart)) + " out of " + str(len(active_user_id)))
11 out of 28
It’s worth noting that there is less than half of the people using tracking heartrate out of 28 active watch users. However, assuming that there is a indicator of a heartrate when the user keeps the watch on and no meter when the watch is off, this dataset would be a good measure to how long a user wears the watch for.
# calculates the watch worn time based on the difference between start and end times of given user and date
def watch_worn_time(df, user_id, date):
user = df[df.Id == user_id]
dates = user[user.new_date == date]
start_time = dates['Time'].iloc[0]
end_time = dates['Time'].iloc[-1]
delta_times = end_time - start_time
#print(start_time)
#print(end_time)
return delta_times / datetime.timedelta(hours=1)
worn_arr = []
date_arr = []
for j in unique_ids_heart:
# filter for the user
user_info = heart_rate[heart_rate.Id == j]
# get unique dates from user
unique_dates= user_info['new_date'].unique()
# for every date the user logged in, calculate the time diff for each day.
for i in unique_dates:
timediff = watch_worn_time(heart_rate,j,i)
worn_arr.append(timediff)
date_arr.append(i)
# date vs hours worn
user_hours_worn = pd.DataFrame()
user_hours_worn['date'] = date_arr
user_hours_worn['hours_worn'] = worn_arr
user_hours_worn
| date | hours_worn | |
|---|---|---|
| 0 | 2016-04-12 | 12.512500 |
| 1 | 2016-04-13 | 12.880556 |
| 2 | 2016-04-14 | 12.827778 |
| 3 | 2016-04-15 | 12.077778 |
| 4 | 2016-04-16 | 13.173611 |
| ... | ... | ... |
| 329 | 2016-05-08 | 14.091944 |
| 330 | 2016-05-09 | 15.506667 |
| 331 | 2016-05-10 | 14.584167 |
| 332 | 2016-05-11 | 15.582778 |
| 333 | 2016-05-12 | 7.967500 |
334 rows × 2 columns
worn_time_mean = user_hours_worn.groupby(['date']).mean()
#average time worn for each day
worn_time_mean.plot(figsize = (18,6))
plt.title("Date vs Average Time worn")
plt.xlabel("Date")
plt.ylabel("Hours worn")
Text(0, 0.5, 'Hours worn')
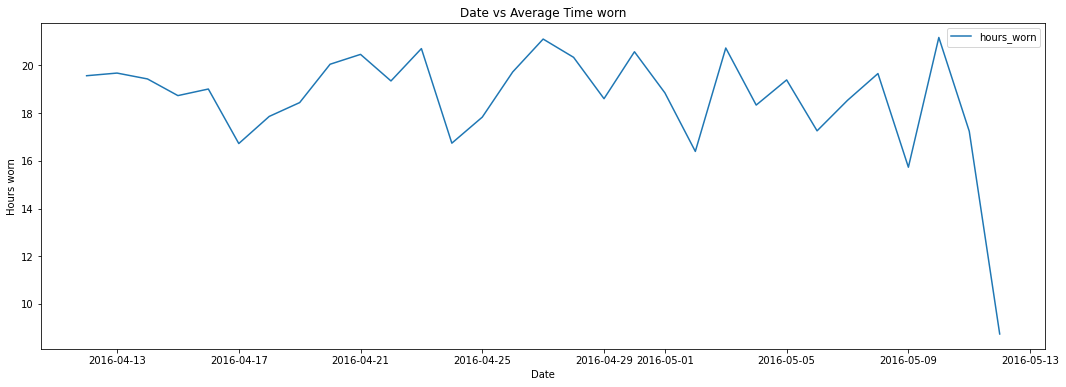
it can be seen that most users wear the watch anywhere from 16 to 22 hours per day. This is probably to track the sleep usage along with. With users wearing for the watch for long periods of time, it might be a good idea to empahsize the watches comfort.
Start and end time analysis
Next, if there is a concrete time that the watch is worn, it can be another indicator towards if people are inclined to wear the watch and sleep, or do people take it off and re-equip it during the day.
def watch_start_end_times(df, user_id, date):
user = df[df.Id == user_id]
dates = user[user.new_date == date]
start_time = dates['Time'].iloc[0]
end_time = dates['Time'].iloc[-1]
return start_time,end_time
# a second function that's slower was created to verify the total time. This runtime is slower but more accurate. Since the results from
# both were similar, the first function can be used.
# def watch_worn_time_2(df, user_id, date):
# user = df[df.Id == user_id]
# dates = user[user.new_date == date]
# display()
# accumulative_time = datetime.timedelta(0)
# for i in range(0,len(dates)-1):
# delta_times = dates['Time'].iloc[i+1] - dates['Time'].iloc[i]
# accumulative_time += delta_times
# return accumulative_time
# watch_worn_time_2(heart_rate,unique_ids_heart[0],unique_dates[16])
start_times = []
end_times = []
for j in unique_ids_heart:
# filter for the user
user_info = heart_rate[heart_rate.Id == j]
# get unique dates from user
unique_dates= user_info['new_date'].unique()
# for every date the user logged in, calculate the time diff for each day.
for i in unique_dates:
st_time, end_time = watch_start_end_times(heart_rate,j,i)
start_times.append(st_time)
end_times.append(end_time)
len(start_times)
len(end_times)
334
user_start_end_times = pd.DataFrame()
user_start_end_times['start_times'] = start_times
user_start_end_times['end_times'] = end_times
user_start_end_times
| start_times | end_times | |
|---|---|---|
| 0 | 2016-04-12 07:21:00 | 2016-04-12 19:51:45 |
| 1 | 2016-04-13 07:01:00 | 2016-04-13 19:53:50 |
| 2 | 2016-04-14 07:49:10 | 2016-04-14 20:38:50 |
| 3 | 2016-04-15 07:37:05 | 2016-04-15 19:41:45 |
| 4 | 2016-04-16 07:53:30 | 2016-04-16 21:03:55 |
| ... | ... | ... |
| 329 | 2016-05-08 07:38:24 | 2016-05-08 21:43:55 |
| 330 | 2016-05-09 06:42:34 | 2016-05-09 22:12:58 |
| 331 | 2016-05-10 06:55:26 | 2016-05-10 21:30:29 |
| 332 | 2016-05-11 06:56:53 | 2016-05-11 22:31:51 |
| 333 | 2016-05-12 06:46:25 | 2016-05-12 14:44:28 |
334 rows × 2 columns
user_start_end_times['start_times_new'] = [d.time() for d in user_start_end_times['start_times']]
user_start_end_times['end_times_new'] = [d.time() for d in user_start_end_times['end_times']]
user_start_end_times
| start_times | end_times | start_times_new | end_times_new | |
|---|---|---|---|---|
| 0 | 2016-04-12 07:21:00 | 2016-04-12 19:51:45 | 07:21:00 | 19:51:45 |
| 1 | 2016-04-13 07:01:00 | 2016-04-13 19:53:50 | 07:01:00 | 19:53:50 |
| 2 | 2016-04-14 07:49:10 | 2016-04-14 20:38:50 | 07:49:10 | 20:38:50 |
| 3 | 2016-04-15 07:37:05 | 2016-04-15 19:41:45 | 07:37:05 | 19:41:45 |
| 4 | 2016-04-16 07:53:30 | 2016-04-16 21:03:55 | 07:53:30 | 21:03:55 |
| ... | ... | ... | ... | ... |
| 329 | 2016-05-08 07:38:24 | 2016-05-08 21:43:55 | 07:38:24 | 21:43:55 |
| 330 | 2016-05-09 06:42:34 | 2016-05-09 22:12:58 | 06:42:34 | 22:12:58 |
| 331 | 2016-05-10 06:55:26 | 2016-05-10 21:30:29 | 06:55:26 | 21:30:29 |
| 332 | 2016-05-11 06:56:53 | 2016-05-11 22:31:51 | 06:56:53 | 22:31:51 |
| 333 | 2016-05-12 06:46:25 | 2016-05-12 14:44:28 | 06:46:25 | 14:44:28 |
334 rows × 4 columns
start_times_seconds = []
end_times_seconds = []
for t in user_start_end_times['start_times_new']:
seconds = (t.hour * 60 + t.minute) * 60 + t.second
start_times_seconds.append(seconds)
user_start_end_times['start_times_seconds'] = start_times_seconds
for t in user_start_end_times['end_times_new']:
seconds = (t.hour * 60 + t.minute) * 60 + t.second
end_times_seconds.append(seconds)
user_start_end_times['end_times_seconds'] = end_times_seconds
user_start_end_times
| start_times | end_times | start_times_new | end_times_new | start_times_seconds | end_times_seconds | |
|---|---|---|---|---|---|---|
| 0 | 2016-04-12 07:21:00 | 2016-04-12 19:51:45 | 07:21:00 | 19:51:45 | 26460 | 71505 |
| 1 | 2016-04-13 07:01:00 | 2016-04-13 19:53:50 | 07:01:00 | 19:53:50 | 25260 | 71630 |
| 2 | 2016-04-14 07:49:10 | 2016-04-14 20:38:50 | 07:49:10 | 20:38:50 | 28150 | 74330 |
| 3 | 2016-04-15 07:37:05 | 2016-04-15 19:41:45 | 07:37:05 | 19:41:45 | 27425 | 70905 |
| 4 | 2016-04-16 07:53:30 | 2016-04-16 21:03:55 | 07:53:30 | 21:03:55 | 28410 | 75835 |
| ... | ... | ... | ... | ... | ... | ... |
| 329 | 2016-05-08 07:38:24 | 2016-05-08 21:43:55 | 07:38:24 | 21:43:55 | 27504 | 78235 |
| 330 | 2016-05-09 06:42:34 | 2016-05-09 22:12:58 | 06:42:34 | 22:12:58 | 24154 | 79978 |
| 331 | 2016-05-10 06:55:26 | 2016-05-10 21:30:29 | 06:55:26 | 21:30:29 | 24926 | 77429 |
| 332 | 2016-05-11 06:56:53 | 2016-05-11 22:31:51 | 06:56:53 | 22:31:51 | 25013 | 81111 |
| 333 | 2016-05-12 06:46:25 | 2016-05-12 14:44:28 | 06:46:25 | 14:44:28 | 24385 | 53068 |
334 rows × 6 columns
average_start_wear = user_start_end_times['start_times_seconds'].mean()
average_end_wear = user_start_end_times['end_times_seconds'].mean()
print(str(datetime.timedelta(seconds=average_start_wear)))
print(str(datetime.timedelta(seconds=average_end_wear)))
3:18:03
22:00:21.365269
It can’t be confirmed that users like to take off their watches to sleep. However, it slightly supports the notion of less users wearing it to bed.
Conclusions and Recomendations
Based on the analysis of fitbit data. Three recomendations can be made for the general marketing strategy for smartwatches.
1. Focus on the branding for activity tracking
Data shows that most users use the smartwatch for tracking their activity throughout the day rather than monitoring their sleep. It will be beneficial to capitalize on this and advertise the watch a watch able to do that. However, it can be noted that there is potential to also market the watch as a sleep tracker.
2. Emphasize ease of use and a good health tracking tool.
Smartwatch users wearing the watch do not perfrom high intensity for the large majority of the time. This means that the watch will be used less as a workout aid, but rather as a general health tracker. If it’s used in this setting, then it will be best for bellabeat to emaphsize the simplicty of the interface rather than it’s capabilities for advaced computations for athlete level tracking.
3. Market towards asthetics
Since most users spend long times wearing the watch while inactive and in a more causual setting, it might be good to focus efforts on emphasizing the asthetics of the watch while also stating the comfort of wearing the watch.